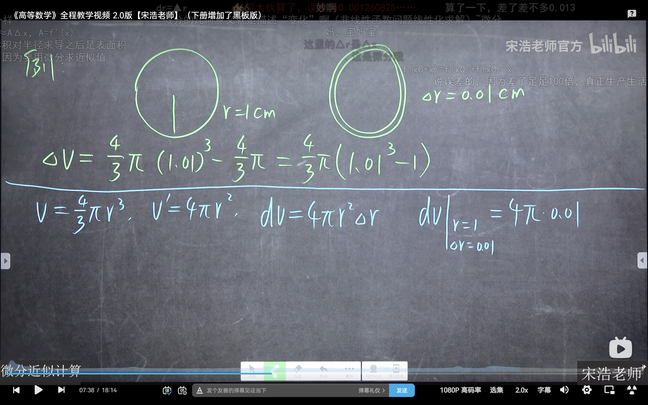
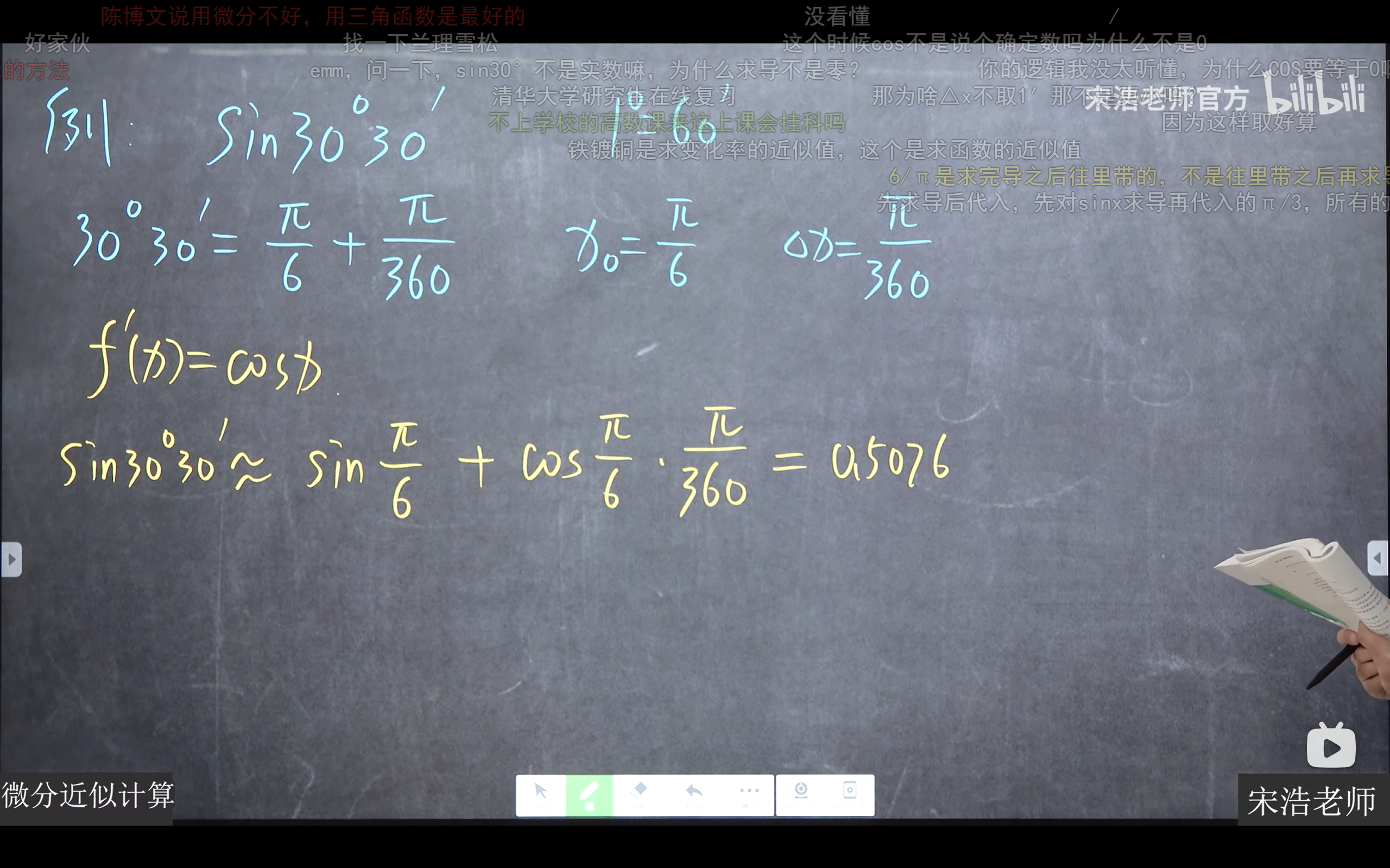
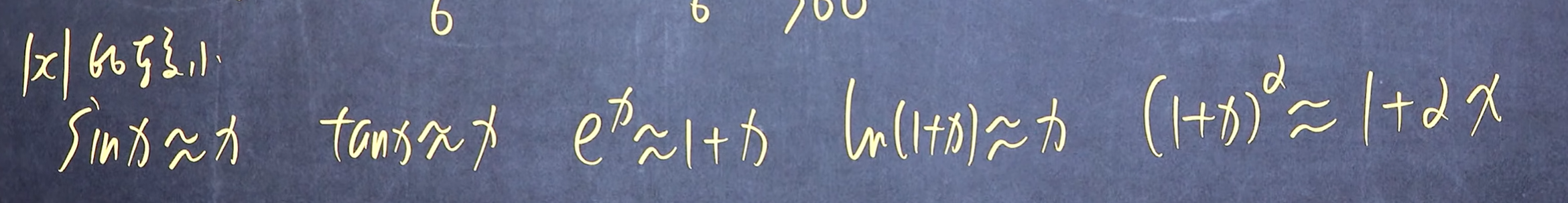linux与WSL
Linux概况
简介
简单来说,linux就是一个自由和开放源码的类 UNIX 操作系统
严格来讲,Linux这个词本身只表示Linux内核,但实际上人们已经习惯了用Linux来形容整个基于Linux内核,并且使用GNU 工程各种工具和数据库的操作系统。
发行版
Linux 的发行版说简单点就是将 Linux 内核与应用软件做一个打包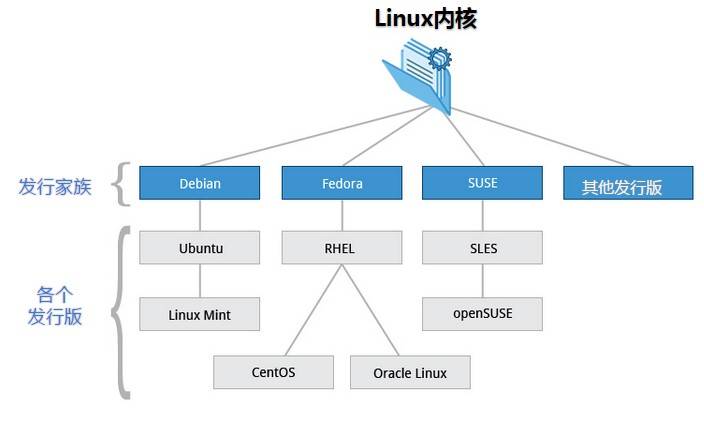
目前市面上较知名的发行版有:Ubuntu、RedHat、CentOS、Debian、Fedora、SuSE、OpenSUSE、Arch Linux、SolusOS 等
文件管理
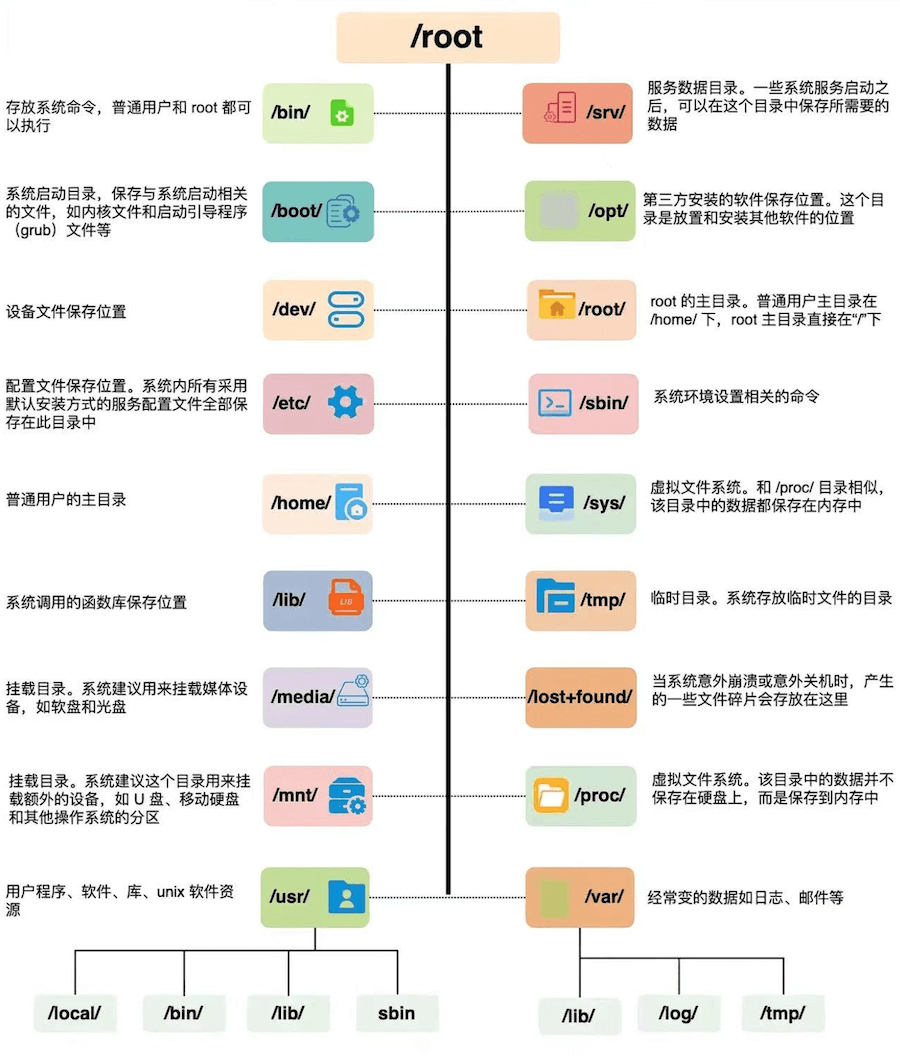
linux的文件资源结构如下图: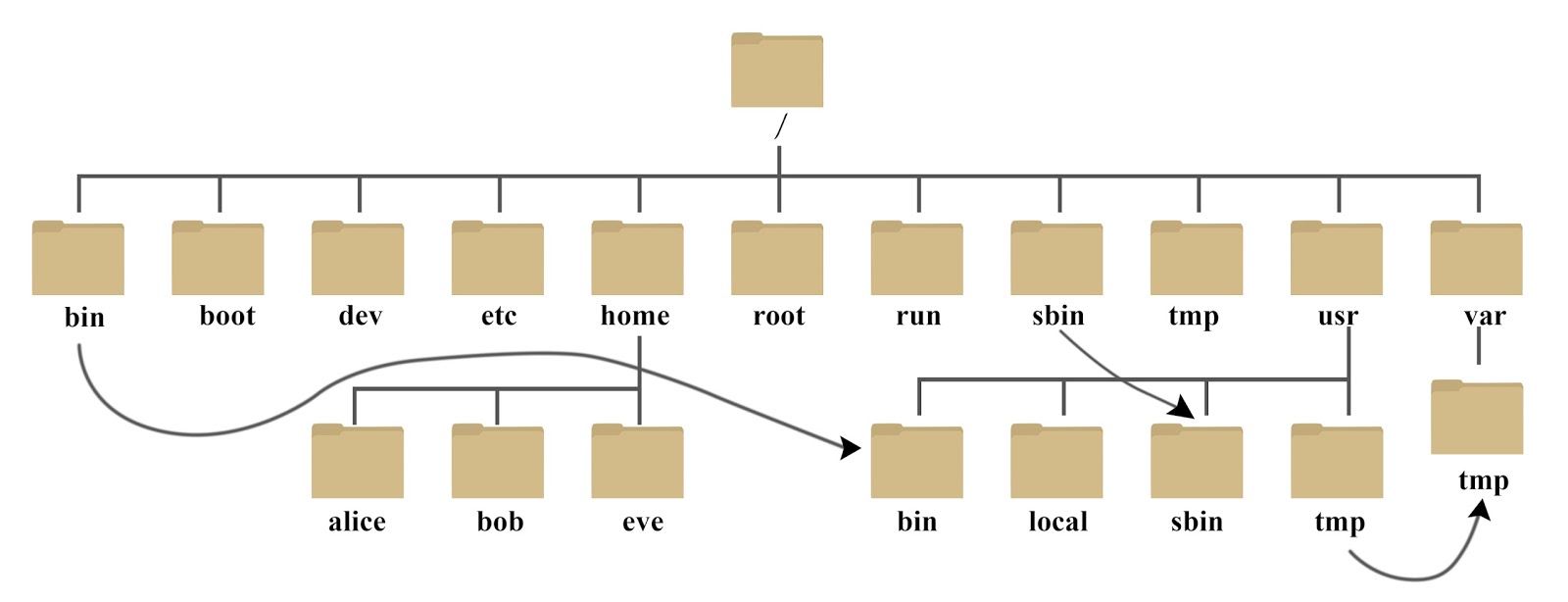
与windows的区别
目前国内 Linux 更多的是应用于服务器上,而桌面操作系统更多使用的是 Windows。主要区别如下
| 比较 | Windows | Linux |
|---|---|---|
| 界面 | 界面统一,外壳程序固定所有 Windows 程序菜单几乎一致,快捷键也几乎相同 | 图形界面风格依发布版不同而不同,可能互不兼容。GNU/Linux 的终端机是从 UNIX 传承下来,基本命令和操作方法也几乎一致。 |
| 驱动程序 | 驱动程序丰富,版本更新频繁。默认安装程序里面一般包含有该版本发布时流行的硬件驱动程序,之后所出的新硬件驱动依赖于硬件厂商提供。对于一些老硬件,如果没有了原配的驱动有时很难支持。另外,有时硬件厂商未提供所需版本的 Windows 下的驱动,也会比较头痛。 | 由志愿者开发,由 Linux 核心开发小组发布,很多硬件厂商基于版权考虑并未提供驱动程序,尽管多数无需手动安装,但是涉及安装则相对复杂,使得新用户面对驱动程序问题(是否存在和安装方法)会一筹莫展。但是在开源开发模式下,许多老硬件尽管在Windows下很难支持的也容易找到驱动。HP、Intel、AMD 等硬件厂商逐步不同程度支持开源驱动,问题正在得到缓解。 |
| 使用 | 使用比较简单,容易入门。图形化界面对没有计算机背景知识的用户使用十分有利。 | 图形界面使用简单,容易入门。文字界面,需要学习才能掌握。 |
| 学习 | 系统构造复杂、变化频繁,且知识、技能淘汰快,深入学习困难。 | 系统构造简单、稳定,且知识、技能传承性好,深入学习相对容易。 |
| 软件 | 每一种特定功能可能都需要商业软件的支持,需要购买相应的授权。 | 大部分软件都可以自由获取,同样功能的软件选择较少。 |
WSL2
简介
WSL(Windows Subsystem for Linux) 是微软为 Windows 用户提供的一个子系统,它允许你在 Windows 上原生运行 Linux(不是虚拟机,不是双系统),直接使用 Bash、apt、gcc、Python、Node.js 等 Linux 工具
而WSL2则是微软针对WSL系统的诸多不足进行改进后的一个被大众广为接受和使用的版本,相比WSL使用了真正的 Linux 内核(轻量虚拟机),并且支持Docker
因此推荐使用 WSL2,兼容性更强,功能更完整
安装
打开powershell(管理员权限),输入:
1
wsl --install
安装完后,重启一次系统
接着设置默认 WSL 版本为 WSL2
1
wsl --set-default-version 2
然后从 Microsoft Store 安装 Linux 发行版(如 Ubuntu)
这样我们就成功安装了WSL2
接下来我们进行第一次使用linux的初始化:
- 启动linux
- 输入用户名和密码(此时密码不可见,但是存在)
- 完成初始化
这样我们就完成了WSL2的安装和初始化
WSL命令
| 命令 | 说明 |
|---|---|
wsl |
启动默认 Linux |
wsl --list --verbose |
查看已安装的发行版和版本 |
wsl --set-version Ubuntu 2 |
设置 Ubuntu 使用 WSL2 |
wsl --install -d Debian |
安装指定发行版 |
wsl --shutdown |
关闭所有 WSL 实例 |
wsl -e bash |
以 Bash 启动 Linux Shell |
日常使用指南
如何访问 Windows 文件?
在 WSL 中,Windows 文件挂载在 /mnt/c、/mnt/d 等目录:
cd /mnt/c/Users/你的用户名/Desktop
如何访问 WSL 文件?
在 Windows 中访问:
\\wsl$\Ubuntu\home\your_username
或者在资源管理器地址栏输入:\\wsl$
如何在Windows使用Linux内核进行日常开发?
只需要在创建项目时将项目文件夹建在
/home/你的用户名/...
即可
并为项目打上适配Linux的SDK
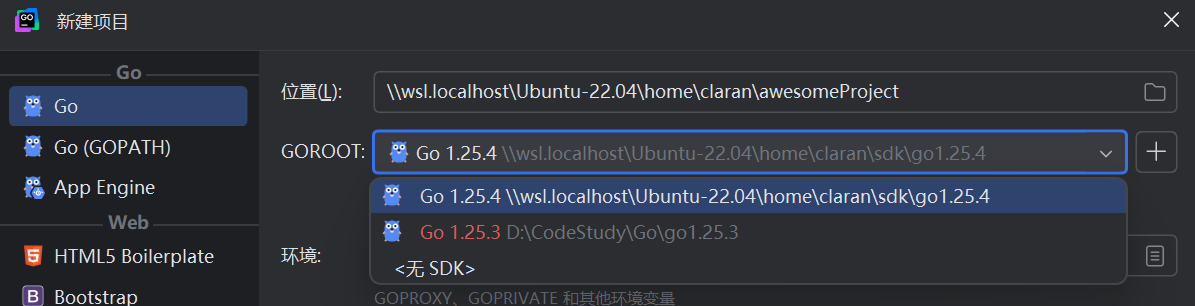
这样我们就能在Win端使用熟悉的Goland进行基于linux内核的日常开发了!