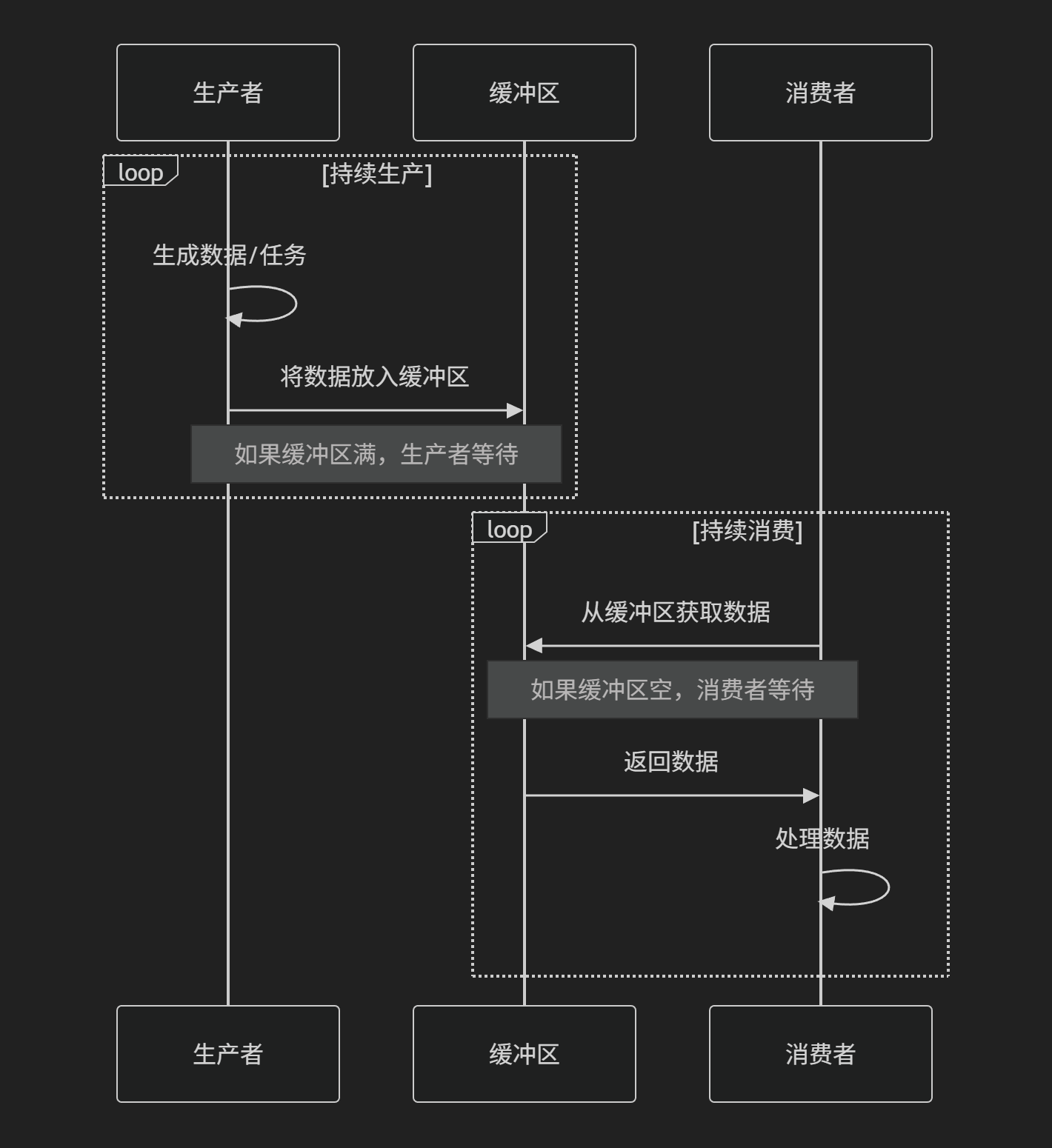
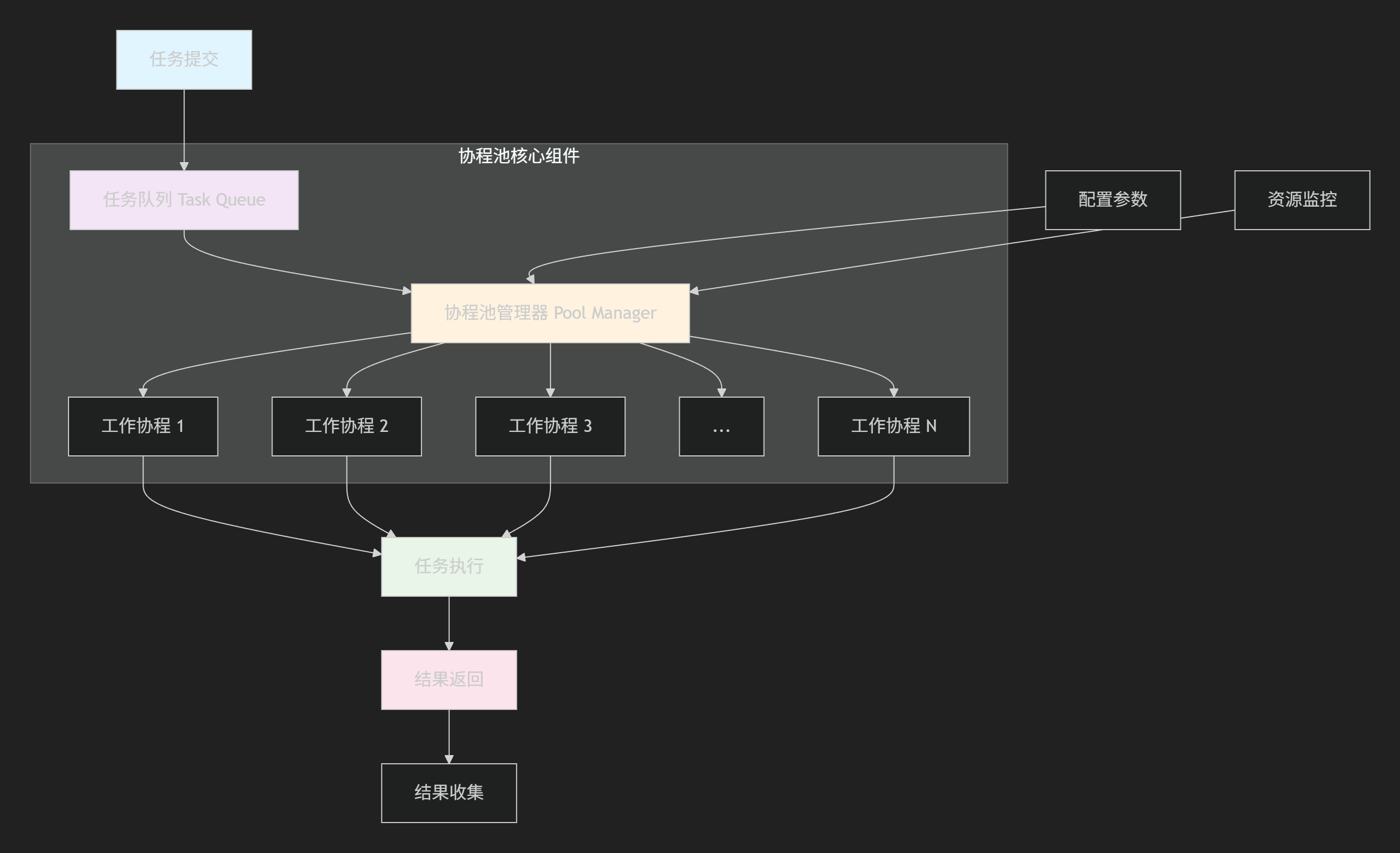
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
|
package main
import (
"Lesson_1/Lanshan-lesson5/service"
"Lesson_1/Lanshan-lesson5/workerPool"
"fmt"
"io/fs"
"os"
"path/filepath"
"runtime"
"sort"
"time"
)
func main() {
if len(os.Args) != 3 {
fmt.Printf("使用方法: %s [目录路径] [搜索关键词]\n", os.Args[0])
os.Exit(1)
}
dir := os.Args[1]
keyword := os.Args[2]
if _, err := os.Stat(dir); os.IsNotExist(err) {
fmt.Printf("目录 '%s' 不存在\n", dir)
os.Exit(1)
}
workerCount := runtime.NumCPU() * 2
fmt.Printf("搜索目录: '%s', 关键词: '%s'\n", dir, keyword)
startTime := time.Now()
pool := workerPool.NewWorkerPool(workerCount, workerCount*100)
paths, err := walkDirectory(dir)
if err != nil {
fmt.Printf("遍历目录错误: %v\n", err)
os.Exit(1)
}
service.SetTotal(int64(len(paths)))
fmt.Printf("发现文件数: %d\n", len(paths))
results := make(chan workerPool.TaskResult, workerCount*100)
done := make(chan bool, 1)
go collectResults(results, done, len(paths))
submittedTasks := 0
for _, path := range paths {
task := service.Task{Path: path, Keyword: keyword}
err := pool.Produce(func() (interface{}, error) {
return service.Search(task)
})
if err != nil {
fmt.Printf("任务提交失败: %v\n", err)
} else {
submittedTasks++
}
}
fmt.Printf("成功提交任务数: %d\n", submittedTasks)
go forwardResults(pool.GetResults(), results)
pool.Close()
close(results)
<-done
total, found, lines := service.GetInfo()
elapsed := time.Since(startTime)
fmt.Printf("\n============= 搜索完成 =============\n")
fmt.Printf("总文件数: %d\n", total)
fmt.Printf("包含关键词的文件数: %d\n", found)
fmt.Printf("总匹配行数: %d\n", lines)
fmt.Printf("耗时: %v\n", elapsed)
submitted, completed := pool.GetInfo()
fmt.Printf("任务提交数: %d\n", submitted)
fmt.Printf("任务完成数: %d\n", completed)
}
func walkDirectory(dir string) ([]string, error) {
var paths []string
err := filepath.WalkDir(dir, func(path string, d fs.DirEntry, err error) error {
if err != nil {
fmt.Printf("访问错误 '%s': %v\n", path, err)
return nil
}
if !d.IsDir() {
paths = append(paths, path)
}
return nil
})
if err != nil {
return nil, err
}
return paths, nil
}
func forwardResults(source <-chan workerPool.TaskResult, dest chan<- workerPool.TaskResult) {
for result := range source {
dest <- result
}
}
func collectResults(results <-chan workerPool.TaskResult, done chan<- bool, total int) {
var finalResults []service.Result
processed := 0
for result := range results {
processed++
if processed%100 == 0 {
progress := float64(processed) / float64(total) * 100
fmt.Printf("处理进度: %d/%d (%.2f%%)\n", processed, total, progress)
}
if searchResult, ok := result.Result.(service.Result); ok {
finalResults = append(finalResults, searchResult)
if len(searchResult.Info) > 0 {
service.AddFound(1)
service.AddLines(int64(len(searchResult.Info)))
}
}
}
fmt.Printf("\n================搜索结果================\n")
printResults(finalResults)
done <- true
}
func printResults(results []service.Result) {
sort.Slice(results, func(i, j int) bool {
return results[i].Path < results[j].Path
})
for _, result := range results {
if result.Err != nil {
fmt.Printf("\n错误: %s - %v\n", result.Path, result.Err)
continue
}
if len(result.Info) > 0 {
fmt.Printf("\n%s:\n", result.Path)
for _, info := range result.Info {
fmt.Printf(" %d: %s\n", info.Line, info.Content)
}
}
}
}
|